
Statistics Post - More Feature, More Problems? A Discussion on Feature Selection and OLS With Examples
It's not as tough as the headline might make it seem!

A few days ago, I got a question from a reader. They work with LLMs (Large Language Models) and were wondering, if you add new features (the word we usually use for variables in machine learning) could that potentially worsen the predictivity of existing features, or the model overall? This is a really good question that gets into important statistics concepts. It also is a nice reminder: if you have any questions on the blog, feel free to reach out through whatever channel (the reader did via twitter DM). So I’ll try to answer that question today starting from a more basic linear regression and then getting into the weeds a little more subsequently.
I think a good way to answer this is to start with a more basic question that’s easier to respond to, and then we can deal with complexity once we have a satisfying starting point.
So to reframe to a more basic question: we have a set of given inputs, X, and we are trying to predict with a model the outputs, Y
We’ll use X as representing our inputs. So let’s say we have two different variables in X; Variable 1 we’ll call X_1 and Variable 2 we’ll call X_2 (please note that this is meant to be a subscript; in textbooks or elsewhere you might see it depicted X₁ and X₂)1 . and Y-hat (ŷ) will represent our predicted output
We can then measure how good our model is by comparing the Y-hat our model predicts for us with Y, aka the actual outputs.
Can we add more variables to our inputs X - for instance Variable 3 which we’ll call X_3 - that would make our model predicting output Y-hat worse?2
The above is a pretty stylized, but it also represents what a great deal of statistics is.
Hopefully if you have been following the Elements of Statistical Learning series this was easy to follow so far - if not, worry not! We’re going to put this in a simpler and more concrete way that should be easier to follow.
I’ll use an example with predicting stock prices - I am a finance guy after all. So let’s try to predict the percent change in a stock’s price.
Luckily for me, I have some data and a good idea on what determines a stock’s price. It turns out, a stock moves in a way that is correlated with the market. A correlation of 1 would mean if the market is up 10%, our stock would be up 10%. If the correlation was -1 it means if the market is up 5% then our stock will go down 5%; they go the opposite direction.
In our example for now we’ll use how much the market went up as our only independent variable and will call it X. Our Y, aka how much the stock actually went up will be the dependent variable. We’ll be trying to make a model that predicts how the stock will move and that’s our Y-hat. The ^ on top of it does look like a hat, imo: ŷ. In fact, any variable we’re predicting will be <that variable>-hat.
The data we have is what we would call our sample. Our goal is to generate an equation or function, that allows us to predict future stock prices. So we’re trying to predict out of sample.
So let’s look at what our dataset might look like so far (again, these are all made up numbers). I’ll reveal later on the actual correlation between a stock and the market from this example.3

Y is dependent variable (after all, it depends on X) and is the actual closing price each day for the stock
X is the independent variable (after all, it is independent of other variables) and in this case is the market’s movement for that day
And we now want an equation for Y-hat (ŷ). We’ll determine how good our equation is by running it for the data we have and comparing the Y-hat that our equation generates with our sample data vs the actual Y.
It might help to illustrate what this looks like in practice. I ran a regression with this data and the results are below:


There’s a lot above, so let’s dig in.
I highlighted it again to show that y (the price that the stock closed at) is our dependent variable.
In this case, we only have 1 variable, which is x1 (how much the market went up or down that day). The coefficient of x1 being .7912 means that we’ll multiply our market move by .7912 in order to get a y-hat.
So we now have the equation:
y-hat (ŷ) or predicted stock price change = x1 (or market move) * .7912
You can see for yourself below:

The R-squared above is a measure of how well our equation does in sample. Generally speaking, a higher R-squared is better, but I also bolded the “in sample” because that’s all R-squared cares about: how well does your equation do with the data in your sample. It’s not uncommon to have a high R-squared in sample, but once you apply it outside the sample, the correlations aren’t as strong. That’s a more in-depth topic for another time, but in fact this is something you see quite often in finance.
And then we finally have the scatter plot. All of the blue dots represent our X and our Y. The trendline is just a representation of y-hat for all the market moves from -5 to 10 (what the scatterplot covers).
Hopefully everything is clear so far. We can now deal with adding another variable and see that they aren’t always necessarily going to improve our model.
Check out the updated dataset below.
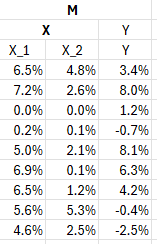
We can see that we still have an input that consists of X, which itself consists of X_1 and X_2. X_1 is the Market Moves. So just an extra variable being X_2, and I’ll explain what it represents shortly. We still have a Y output.
Let’s get a little more technical with our language too. If you’ve worked with Excel before, you’ll likely think of X_1, X_2 and Y as columns. But we’re doing statistics, so henceforth I’ll call them vectors. Nothing changed other than how I’m speaking about them. If you take vectors X_1 and X_2 then that’s our input data or X, and Y is still our output as before. Finally, what if we had a nice way to refer to our X input and Y output altogether - aka the complete image above? That’d be a Matrix. That’s all a matrix is - a bunch of vectors combined. So we can see that in this case we’re using matrix M (matrices are often bolded).
With that language digression out of the way I’ll tell you what vector X_2 represents, which is just X_1 multiplied by another random number. Hopefully you’re asking, “how would adding an additional variable that contains no new relevant information help our model. In fact, could adding another variable that duplicates existing data (in part, after all, X_2 is dependent on X_1) introduce separate issues?”
That’s exactly the point! For the first sentence, adding unrelated information can make a model worse. If I was trying to model the weather, do you think that it would be helpful to add an additional independent variable which is just a vector of people’s heights? No! They’re completely unrelated.
For the second sentence, that is indeed a problem when multiple variables are correlated with each other. We call those variables collinear to each other.
So let’s check out our updated model with the collinear input vectors from above.

So our equations is:
Y-hat, predicted stock change = X_1 (market move) * .7705 + X_2 * .0077
And now I’m finally going to tell you what the actual way that our dependent variable, Y, was calculated.
Y = X_1 * 0.8 + np.random.uniform(-5, 5)
So stock price is just 80% of whatever the Market Move (X_1) is multiplied by a random number between -5 and 5. If you’ll recall, the coefficient for X_1 in the univariate (only one variable, X_1) model above was .7912. Linear Regression can be very powerful.
With that in mind, now look at X_1 above in our bivariate model (two variables, X_1 and X_2) and see that it’s .7705. Again, we know that the actual Y is just X_1 * .8; in this case that is a nice illustration of the fact we’re getting further away from a good model.
We can also see that the model accurately deduced that X_2 isn’t all that helpful for getting an accurate Y-hat (our prediction). The coefficient is only .0077. And it helps too to see a representation of the data inputs and outputs that we’d be using in the equation:
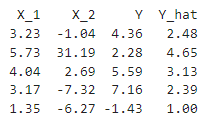
Basic visual inspection should show how unrelated X_2 and Y are and that furthermore, X_2 has little influence on Y-hat.
A final basic point: eagle eyed readers might have noticed that the bivariate model actually has a slightly higher R-squared than the univariate model. As I said above, “It’s not uncommon to have a high R-squared in sample, but once you apply it outside the sample, the correlations aren’t as strong”. The R-squared only looks at how well your predictions work with the data you provide it. After everything we’ve gone through, and even intuitively, I imagine you can now see that our second model would be worse than our first, even with the higher R-squared. And again, I think discussing R-squared further in depth could be helpful but that will have to be another time.
Additional Discussion
We used an OLS model above, but that’s not the only kind of prediction model we could use. In fact, other models are often based around how it deals with all the features (or variables) in the sample.
Some models will begin with every single feature (variable) included at the start, and slowly weed out any variables that would result in model improvements. By the same dint, other models start with no features at the start and then add them one by one.
Ridge Regressions are models that will minimize variable coefficients via a penalty term. In these models it’s important to normalize your features first. What’s that? Well all it means is that each of your features will have a mean (average) of 0. So here’s what one of the features, X_1 would look like normalized.

I suppose it looks less normal to me ;). Jokes aside, there’s a similar regression called a Lasso. It’s more or less the same as a Ridge Regression but it will actually set features coefficients’ equal to 0 (if it’s a bad enough feature) which is equivalent to dropping them from the model.
I’m really ahead of my skis here, but this post came from someone asking me about adding more features in machine learning, Large Language Models (LLMs) specifically. In the modern machine learning that gets talked about often nowadays, they often will use more features because the kinds of complex models they're trying to fit, the increase in computing power, and potential for overfitting or poorly fitting due to poor features is outweighed by the potential relationships between all the features in question that are more complex than smaller scale models can capture, and that also, in theory if well specified, the model can minimize the disruption of poor features. So to sum everything up, yes, poor variable selection can make a model worse. In fact, determining the optimal variables is in many ways one of the key focuses of statistics and machine learning.
Code is below (not including the code for the second regression/example as it’ll take too much space given that the only differences are minor besides X_2, which I generated with “X_2 = X_1 * np.random.uniform(-5, 10, 100)”):
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
# Create a series for X (Market Price) with random numbers from -5 to 10
np.random.seed(0) # Set seed for reproducibility
X = np.random.uniform(-5, 10, 100)
# Create a series for Y using the formula Y = X * 0.8 + random number from -5 to 5
Y = X * 0.8 + np.random.uniform(-5, 5, 100)
# Create a DataFrame to store X and Y
data = pd.DataFrame({'X': X, 'Y': Y})
# Fit OLS model
#X = sm.add_constant(X) # Add constant term for intercept
model = sm.OLS(Y, X).fit()
# Add predicted Y values (Y hat) to the DataFrame
data['Y_hat'] = model.predict(X)
# Visualize the data with a scatter plot and trend line
plt.scatter(data['X'], data['Y'], label='Data')
plt.plot(data['X'], data['Y_hat'], color='red', label='Trend Line') # Plot the trend line
plt.title('Scatter Plot of X vs Y with Trend Line (No Constant Term)')
plt.xlabel('X (Market Price)')
plt.ylabel('Y')
plt.legend()
plt.show()
print(model.summary())
# Round the columns in the DataFrame to 2 decimal places
rounded_data = data.round(2)
print(rounded_data.head())
In fact, this is a pretty common convention. You can have a matrix X which is bolded, but if you wanted to access the first column or vector (whatever you prefer to call the variable) in X then you would use X₁. So it’s pretty generalizable that the subscript indicates the first element of whatever X is, be it vector or matrix or something else. Trying to just internalize these mathematical notations is really helpful, and the best way is with repetition. That said, many textbooks don’t help this way! I am trying to repeat what I say often so apologies if you’re already familiar with Y-hat being our prediction and so on, but it’s meant to help people get used to these shorthands.
This is done by going over the dataset, using the equation to produce Y-hat, and then comparing each Y (actual output) - Y-hat. We’re trying to minimize the sum of all those Y - Y-hats.
This is an actual measure. It’s called a stock’s beta. In this case, I generated the data myself with a beta I made up. It’s not super accurate, but hey, if I actually was able to predict stock prices accurately, I wouldn’t be giving it away in this free blog ;)